AWS Lambda “cron”: un esempio didattico
Da anni il serverless computing è utilizzato in diversi ambiti: in questo articolo cercheremo di introdurre l'argomento tramite un esempio didattico utilizzando AWS Lambda, il primo servizio di questo tipo a essere stato reso pubblico e attualmente il più documentato.


Introduzione
Da anni il serverless computing è utilizzato in diversi ambiti: in questo articolo cercheremo di introdurre l'argomento tramite un esempio didattico utilizzando AWS Lambda, il primo servizio di questo tipo a essere stato reso pubblico e attualmente il più documentato.
AWS descrive il servizio in questo modo:
AWS Lambda consente di eseguire codice senza dover effettuare il provisioning né gestire server. Le tariffe sono calcolate in base ai tempi di elaborazione, perciò non viene addebitato alcun costo quando il codice non è in esecuzione.
Quando il problema può essere risolto con limiti ben noti di memoria, di calcolo e di dimensioni dell'installato, questa può essere una soluzione comoda e affidabile.
Ci sono tre scenari tipici:
- un web service;
- un trigger in conseguenza di una variazione all'interno di un servizio AWS;
- un worker crontab indipendente.
In questo articolo tratteremo il terzo tipo, con un caso di “sentinella”: si deve eseguire un'operazione distribuita (per esempio la copia di un file tra un server e S3) e venir avvisati in caso di problemi. Lasciare il programma sul server di origine impedirebbe, in caso di guasti, l'inoltro della notifica, mentre un servizio terzo con un'affidabilità molto alta ridurrebbe il rischio.
I passi possono essere riassunti così:
- su di un server, un processo produce un file;
- sul server stesso, un altro processo esporta periodicamente il file su di un bucket S3 all'orario
t1; - sempre periodicamente, una funzione lambda – all'orario
t2– controlla che su S3 ci sia un nuovo file: sia per il caso positivo che per quello negativo, un bot Telegram avviserà un gruppo dell'esito dell'operazione.
Lo schema architetturale può essere rappresentato in questo modo:
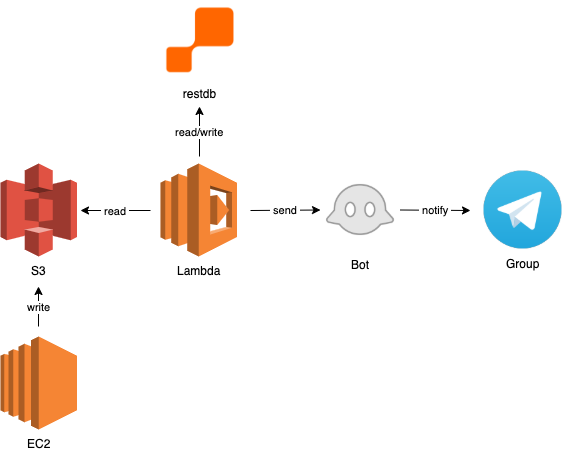
Per realizzare il precedente punto 3, si può utilizzare un qualsiasi metodo che permetta di confrontare un dato letto da S3 (in memoria, dal punto di vista della lambda) con un dato persistente: ricordiamo infatti che una lambda non può scrivere su di un proprio file system e qualsiasi risorsa alla quale accede deve di fatto essere un “servizio”. In questo caso, per semplicità abbiamo scelto restdb.io ma avremmo potuto utilizzare – restando nel mondo AWS – DynamoDB o un'altra soluzione: per ragioni didattiche, restiamo su servizi gestiti, senza dover quindi installare alcunché.
Prerequisiti
Per poter iniziare, serve:
- creare un bucket S3 con gli opportuni privilegi di lettura e scrittura;
- avere ovviamente un proprio programma che scriva sul bucket;
- su restdb.io, creare una tabella con un singolo campo (abbiamo scelto di chiamarlo
objName); - creare un bot telegram, aggiungerlo a un gruppo ed estrarre l'id del gruppo stesso.

Inizio
Per rendere le operazioni molto più semplici, utilizzeremo il framework serverless e, tra i linguaggi supportati, Python per semplicità. Suggeriamo inoltre di installare Serverless Python Requirements e Serverless Offline.
Lanciando serverless, uno scaffolder crea un progetto dal quale partire: nel nostro caso, sorvolando momentaneamente sulle funzioni interne, il file handler.py potrebbe essere costituito da un'unica funzione, chiamata per esempio run, come la seguente, che mappa bene quanto precedentemente descritto:
import boto3
import json
import os
import requests
from requests.exceptions import HTTPError
import sys
###
### qui le funzioni descritte in seguito
###
def run(event, context):
last_obj_s3 = last_added()
last_obj_db = restdb_get()
chat = os.environ["BOT_CHAT_ID"]
if (last_obj_s3['Key'] != last_obj_db[0]['objName']):
restdb_put(last_obj_s3['Key'])
telegram_bot_sendtext_chat('✅ dump is ok', chat)
else:
telegram_bot_sendtext_chat('❌ dump is too old', chat)
return {
"statusCode": 200,
"body": '{}'
}
Le variabili d'ambiente sono valorizzate nel file serverless.yml, come vedremo più avanti.
La funzione last_added() serve ad ottenere il nome dell'ultimo oggetto aggiunto sul bucket: AWS imposta un limite di restituzione di 1000 elementi per la sua chiamata list_objects_v2, quindi non si può lasciar crescere indefinitamente il numero di oggetti aggiunti sul bucket.
def last_added():
get_last_modified = lambda obj: int(obj['LastModified'].strftime('%s'))
s3 = boto3.client(
's3',
aws_access_key_id=os.environ["KF_AWS_ACCESS_KEY_ID"],
aws_secret_access_key=os.environ["KF_AWS_SECRET_ACCESS_KEY"]
)
objs = s3.list_objects_v2(Bucket=os.environ["KF_AWS_S3_BUCKET"])['Contents']
last_added = [obj for obj in sorted(objs, key=get_last_modified)][-1]
return last_added
Per estrarre il nome del file precedentemente memorizzato come ultimo, la funzione è la seguente:
def restdb_get():
r = None
url = os.environ["RESTDB_URL"]
headers = {
'Accept': 'application/json, */*',
'Content-type': 'application/json',
'X-ApiKey': os.environ["RESTDB_APIKEY"]
}
try:
response = requests.get(url, headers=headers)
# response.raise_for_status()
r = response.json()
except HTTPError as http_err:
print('HTTP error occurred in ' + os.environ["KF_AWS_S3_BUCKET"] + ' restdb_get()')
sys.exit(0)
except Exception as err:
print('Other error occurred in ' + os.environ["KF_AWS_S3_BUCKET"] + ' restdb_get()')
sys.exit(0)
return r
Gli output delle eccezioni verranno inviate in stdout e quindi nei CloudWatch che serverless creerà per noi (possono certamente essere messe in pratica soluzioni più raffinate).
La scrittura del dato su DB a questo punto è davvero simile alla lettura:
def restdb_put(objName):
r = None
url = os.environ["RESTDB_URL"] + os.environ["RESTDB_TABLE"]
headers = {
'Accept': 'application/json, */*',
'Content-type': 'application/json',
'X-ApiKey': os.environ["RESTDB_APIKEY"]
}
data = {'objName': objName}
try:
response = requests.put(url, headers=headers, data=json.dumps(data))
r = response.json()
except HTTPError as http_err:
print('HTTP error occurred in ' + os.environ["KF_AWS_S3_BUCKET"] + ' restdb_put()')
sys.exit(0)
except Exception as err:
print('Other error occurred in ' + os.environ["KF_AWS_S3_BUCKET"] + ' restdb_put()')
sys.exit(0)
return r
Infine l'ultima funzione, per la chiamata al bot che segnalerà il gruppo del successo o del fallimento dell'intera sequenza (posto che non ci siano fallimenti intermedi, nel cui caso si dovrà – in questa semplice realizzazione – risalire ai log):
def telegram_bot_sendtext_chat(bot_message, bot_chatID):
bot_token = os.environ["BOT_TOKEN"]
send_text = os.environ["BOT_API_PREFIX"] + bot_token + \
'/sendMessage?chat_id=' + str(bot_chatID) + '&parse_mode=Markdown&text=' + \
bot_message
response = requests.get(send_text)
return response.json()
Configurazione
service: kiwibot-lambda-python-out
provider:
name: aws
runtime: python3.7
# cfnRole: arn:aws:iam::000000000000:user/xxxxxxxxxxxx
region: eu-west-1
environment:
BOT_API_PREFIX: 'https://api.telegram.org/bot'
BOT_CHAT_ID: '-xxxxxxxxx'
BOT_TOKEN: 'xxxxxxxxxx:xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
KF_AWS_ACCESS_KEY_ID: 'xxxxxxxxxxxxxxxxxxxx'
KF_AWS_SECRET_ACCESS_KEY: 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
KF_AWS_S3_BUCKET: 'xxx'
RESTDB_APIKEY: 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
RESTDB_TABLE: '/xxxxxxxxxxxxxxxxxxxxxxxx'
RESTDB_URL: 'https://xxxxxxxxxxx-xxxx.restdb.io/rest/xxxxxxxx'
plugins:
- serverless-offline
- serverless-python-requirements
functions:
hello:
handler: handler.run
events:
- schedule:
rate: cron(0 22 * * ? *)
Dopo le precedenti spiegazioni, l'unica riga interessante rimane quella, con sintassi cron, per indicare quando eseguire la lambda (in questo caso, tutti i giorni alla 22:00 UTC).
Il package.json è molto semplice
{
"name": "kiwibot-lambda-python-out",
"description": "",
"version": "0.1.0",
"dependencies": {},
"devDependencies": {
"serverless-offline": "^5.12.1",
"serverless-python-requirements": "^5.0.1"
}
}
Mentre per quanto riguarda i pacchetti Python, il requirements.txt sarà molto breve, avendo di fatto interessato solo la librerie boto3 per i servizi di AWS, requests e le loro dipendenze.
boto3==1.10.30
botocore==1.13.30
certifi==2019.11.28
chardet==3.0.4
docutils==0.15.2
idna==2.8
jmespath==0.9.4
python-dateutil==2.8.0
requests==2.22.0
s3transfer==0.2.1
six==1.13.0
urllib3==1.25.7
Ripetendo il freeze dei pacchetti, tra qualche tempo naturalmente i numeri di versione potrebbero variare.
Debug e deploy
# deploy complessivo
serverless deploy --aws-profile {aws-profile} \
--aws-region {aws-region} --stage dev --region {region}
# deploy function
serverless deploy function -f {function-name} \
--aws-profile {aws-profile} --aws-region {aws-region} --stage dev --region {region}
# deploy config
serverless deploy function -f {function-name} --update-config \
--aws-profile {aws-profile} --aws-region {aws-region} --stage dev --region {region}
# remove
serverless remove --aws-profile {aws-profile} \
--aws-region {aws-region} --stage dev --region {region}
# debug offline
serverless offline
Negli esempi di comandi bash precedenti, aws-profile è il nome del profilo scelto in ~/.aws/credentials, mentre dev è lo stage scelto (si veda la documentazione sul sito di serverless per approfondimenti.
Conclusioni
Senza dimenticare i limiti indicati all'inizio dell'articolo, questo semplice esempio dovrebbe essere utile per far comprendere le potenzialità del mondo serverless.
--
Foto di copertina di Ashton Bingham disponibile su Unsplash