AWS Machine Learning: un esempio didattico
Amazon Machine Learning è un servizio AWS davvero interessante che richiede una competenza di base. Lo abbiamo provato per capirne le potenzialità e la semplicità utilizzando il dataset standard "Titanic" (Kaggle).


Introduzione
Da almeno un paio d'anni sono disponibili in rete vari servizi di Machine Learning (Amazon, Google, IBM, Microsoft ecc...). Dopo averne osservati diversi, mi sembra di poterli classificare in un paio di modi:
- Per specificità del compito:
- rivolti a un compito specifico (riconoscimento del parlato, dei testi, delle immagini eccetera);
- generali, per programmatori o ricercatori (spesso tramite soluzioni IaaS/PaaS, più di rado FaaS).
- Per competenza richiesta:
- è necessaria una profonda conoscenza dell'argomento (indipendentemente dall'essere o meno un sistema gestito);
- può bastare una competenza di base.

Amazon Machine Learning è un servizio AWS davvero interessante che richiede una competenza di base. Molto spesso non sono richiesti risultati di accuratezza elevatissima e, altrettanto frequentemente, il problema da trattare è riconducibile al caso più comune: addestrare un classificatore binario. Per scenari come questo, AWS ML sembra offrire parecchi vantaggi. Fornendo semplicemente dei CSV di training e di testing, AWS ML è in grado di generare - senza alcuna competenza richiesta da parte dell'utente - un modello di apprendimento e, volendo, di rendere disponibile online il modello stesso.
Avevo già provato questo servizio lo scorso anno: con l'apertura del nostro blog ho pensato di riprovare per vedere se fosse cambiato in qualche modo. L'ho quindi provato con un problema "giocattolo" (a me interessava vedere la comodità del workflow più che l'abilità del servizio nel trattare problemi complessi) e ho scelto uno dei più semplici e celebri dataset: Titanic (Kaggle). Come tutti sanno, si tratta semplicemente di prevedere se un passeggero con determinate caratteristiche sopravviverà o meno al noto disastro.
Secondo alcuni, una previsione sul testing set compresa nell'intorno del 78-80% è da considerarsi un risultato medio. Mi incuriosiva sapere se, evitando praticamente di aiutarlo, AWS ML avrebbe ottenuto un risultato in quell'intervallo.
Altra informazione che tornerà utile: non tutti i passeggeri avevano la stessa probabilità di salvezza e, da varie analisi presenti in letteratura, risulta che i ricchi erano avvantaggiati rispetto ai poveri, le donne rispetto agli uomini e i giovani rispetto agli anziani... una giovane donna ricca, anche senza Di Caprio, se la sarebbe cavata alla grande 😜.
La prova, per passi
Dato che non voglio aiutarlo, inizio con l'opzione di base.

Carico il CSV di training in un bucket S3 e il wizard mi chiede di poter aggiungere i permessi in lettura. Il CSV è grezzo, senza alcuna elaborazione.
ML riconosce correttamente i tipi (qui si vedono le prime dieci delle dodici feature)...

...e mi chiede di scegliere la proprietà target.

Naturalmente scelgo survived come obiettivo.
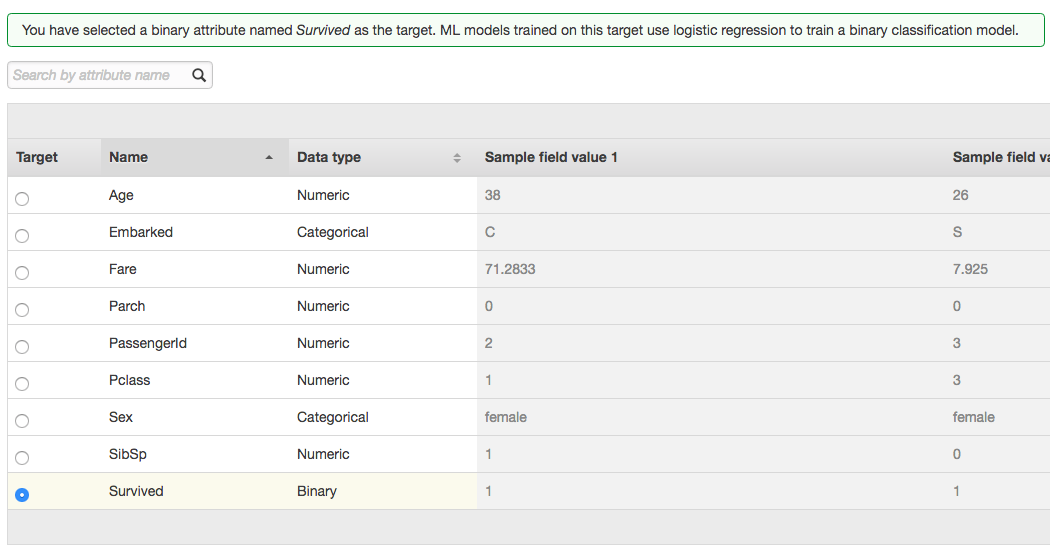
Mi chiede anche un parametro opzionale per l'identificazione dei record e, infine, lascio che apprenda senza alcun aiuto utilizzando le sue opzioni predefinite (gli ho solo impedito di classificare come categoria la feature Cabina, lasciando che venisse indicata come semplice testo).

Dopo due minuti di "riflessione", AWS ML ha creato un modello per il dataset di training.
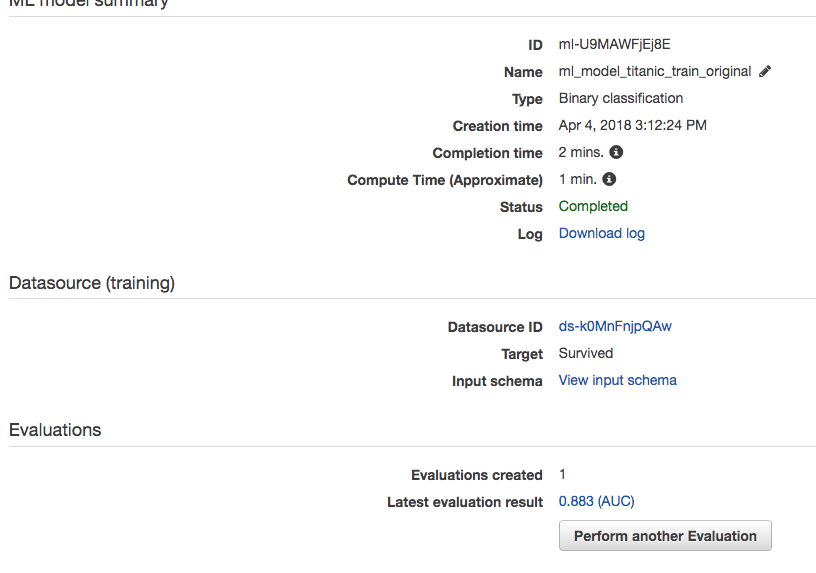
Ora è il momento di validare il modello sul dataset di testing e quindi scelgo l'opzione "Generate batch predictions".
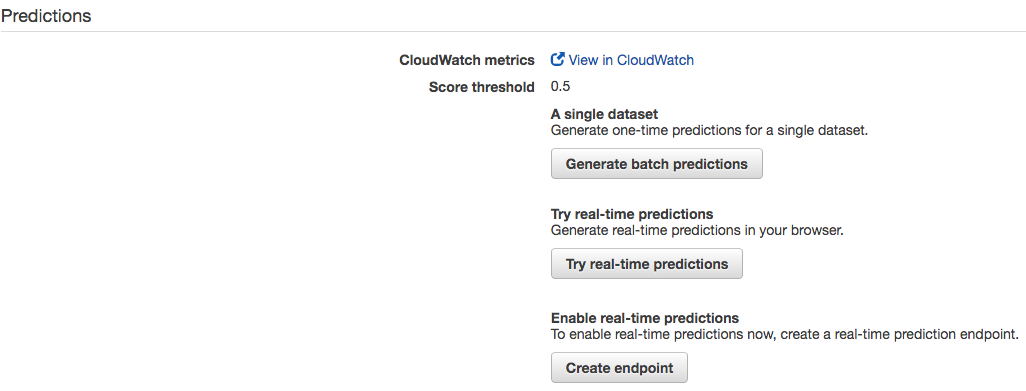
Il sistema mi chiede dove depositare i risultati che elaborerà e indico lo stesso S3 di partenza.

Vengo inoltre informato che la verifica costerà 0.1 $ per ogni mille dati ma avendo poche centinaia di passeggeri da validare, spenderò pochi centesimi 😃.
Ora nel mio bucket c'è un file csv.gz con la predizione: nella fotografia, ho oscurato i risultati iniziali (voglio essere molto scrupoloso nel seguire certe regole di Kaggle).
Con una semplice elaborazione, rinomino i campi della prima riga come vuole Kaggle e rimuovo lo score ché non verrebbe accettato dal validatore automatico di Kaggle stesso.
Ora è il grande momento: inviare il CSV a Kaggle e farlo valutare (né io, né AWS ML sappiamo quali passeggeri siano realmente sopravvissuti ma Kaggle sì).

Molto bene! AWS ML, senza praticamente alcun aiuto e senza alcun raffinamento, ha ottenuto un risultato di qualità media (quasi il 79%).
Mandiamo online il giocattolo
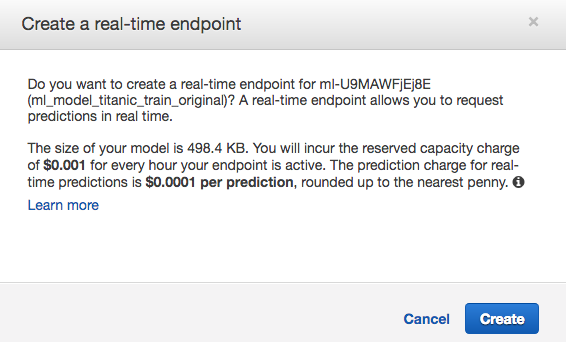
Immaginando di essere soddisfatto del mio risultato, voglio creare un servizio HTTPS in grado di rispondere alla generica domanda: il passeggero descritto da certe caratteristiche, è sopravvissuto?
Scelgo quindi "Create a real-time endpoint" e vengo preavvisato dei costi contenuti che dovrò sostenere per ogni richiesta che verrà indirizzata al mio servizio... che comunque terrò acceso solo per il tempo della prova 😜.

AWS ML fornisce un'interfaccia client per testare il server: ricordate la giovane donna ricca? Inserisco i dati di un fittizio povero uomo anziano (sessant'anni, niente famiglia, terza classe, biglietto economico, nessuna cabina... una tristezza inifinta: non so bene cosa volesse andare a fare in America ma è un esempio volutamente estremo).
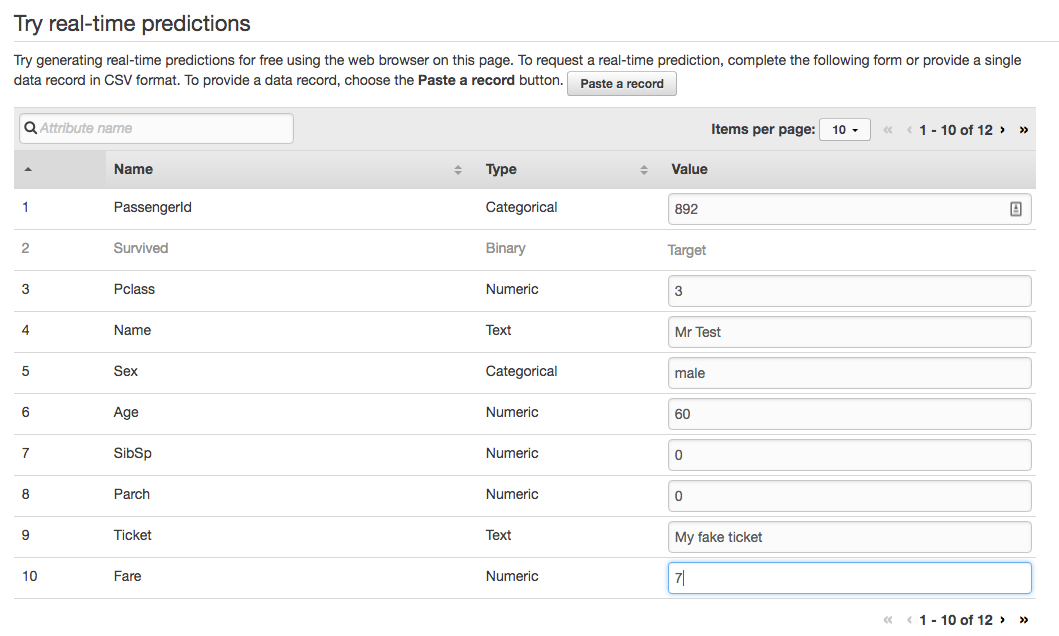

Lanciamo la previsione...

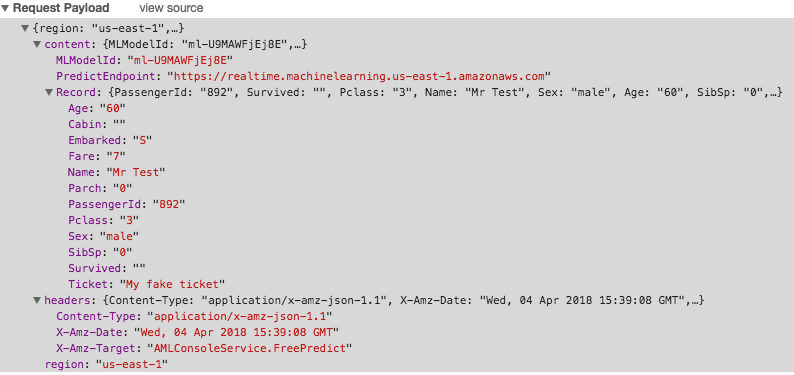
...come si può notare dal JSON, AWL ML ritiene estremamente probabile che il nostro ipotetico passeggero non sopravviverà al naufragio.
E' inoltre possibile (ho usato Chrome) vedere come venga inviato il JSON del passeggero nel payload della richiesta.
Conclusioni
AWS Machine Learning ha un workflow davvero comodo per la prototipazione di modelli per problemi semplici: c'è naturalmente la questione del lock-in ma per certe situazioni potrebbe non essere un problema. Il più recente e raffinato AWS SageMaker potrebbe essere un'interessante evoluzione all'interno della famiglia.
PS: Foto di copertina di Руслан Гамзалиев su Unsplash