Carichi impulsivi con AWS Lambda API Gateway: un esempio didattico


Problema
Come caricare lecitamente un server del maggior numero di richieste nel minor tempo possibile, senza avere una infrastruttura dedicata?
Possibili soluzioni disponibili
- Certamente lanciare tante connessioni “a mano” è un metodo troppo elementare e che non raggiunge grandi quantità di richieste;
- utilizzare Locust può essere una soluzione semplice ma risente in questo modo dei limiti della banda disponibile e dei limiti della macchina ospitante, che sia locale o in cloud;
- sempre Locust può essere utilizzato con un'architettura distribuita ma non è certo immediata da impostare, pur potendo, in quel caso, raggiungere anche milioni di richieste.
Soluzione sviluppata
AWS Lambda, tramite API gateway permette, per una data region, di arrivare, in alcune casi come l'Irlanda (eu-west-1) fino a tremila connessioni: visto che quello che mi interessava era, senza infrastruttura, arrivare a qualcosa di simile ad un un “gradino” di richieste, ho pensato al seguente schema.
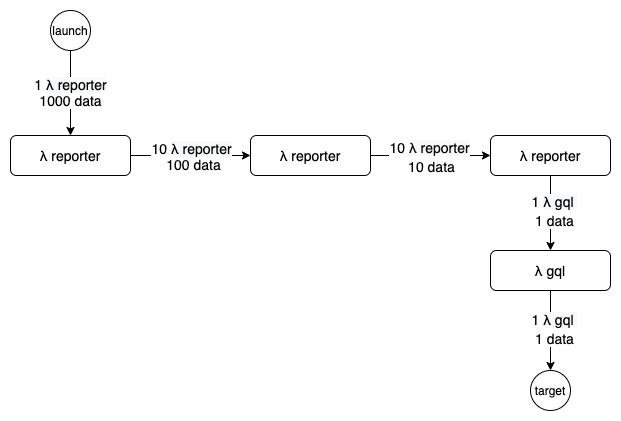
Una sola chiamata lambda, con un payload utile per costruire 1000 chiamate personalizzate verso il server target, effettua, verso se stessa, 10 richieste, ciascuna con un payload da 100: in modo simile a uno spawn di processi ma con normali chiamate REST JSON e così via fino ad arrivare a una singola chiamata, la quale chiamerà una lambda “GraphQL” che farà la vera richiesta verso il server target.
Naturalmente il target può essere GraphQL o meno, non importa.
In questo modo, in meno di tre secondi, si arriva a mille richieste, pagando poi solo per il numero effettivo di chiamate, traffico che potrà poi essere sostenuto ripetendo periodicamente, ad esempio ogni due secondi, la singola chiamata iniziale.
Il codice di lambda-load è disponibile su GitHub e utilizza, come esempio di target, il famoso servizio GraphQL https://countries.trevorblades.com/ per i dati dei Paesi del mondo.
Nella cartella rest_test ci sono degli esempi JSON che possono essere utilizzati per esempio con HTTPie per provare, sia in locale che in remoto, i due endpoint sviluppati: reporter e graphql. L'URI complessivo della API graphql, per semplicità, è indicata nel file yml ed è quindi personalizzabile come variabile d'ambiente GQL_SAME: questo richiede quindi almeno due build ma questo passaggio può certamente essere migliorato o sostituito in fase di personalizzazione.
--
Photo by Simon Maage on Unsplash