Google AutoML Vision: un esempio didattico
Volevo fare un esercizio di object detection e mi sono imbattuto in Google Cloud AutoML. In questo articolo descriverò la mia esperienza e condividerò l'essenza del codice sviluppato.


Introduzione
Volevo fare un esercizio di object detection: ci sono molti eccellenti tutorial in giro ma:
- mettere insieme i pezzi richiede tempo (spesso una cosa funziona di uno e un'altra di un altro);
- non ho una GPU sul portatile… e lo accendo e lo mando in pausa relativamente spesso;
- ci sono ottimi sistemi cloud tipo “notebook” ma è comunque un procedimento laborioso;
- alla fine, in questa fase, mi serviva un Proof of Concept;
- ho incontrato Google Cloud AutoML e non ho trovato niente di simile come qualità, prezzo, tempo e semplicità.
In questo articolo descriverò la mia esperienza e, alla fine, indicherò dove trovare l'essenza del codice.
La preparazione
Nei giorni durante i quali iniziai a pensare a questo problema, al lavoro si parlava, in ambito di Machine Learning, sia di ciliegie che di ferri chirurgici: non essendo la stagione delle ciliegie, subito pensai ai mandarini 😀 ma chi mi avrebbe potuto garantire che avrei finito le mie prove prima che fossero terminati? Non potevo certo, inoltre, avere la certezza di fotografarne abbastanza per le prove senza aver bisogno in seguito di nuove fotografie.
Avevo bisogno di qualcosa di più duraturo.
Scartati i mandarini, per similitudine con i ferri, pensai ai cucchiai. 😀 Non volevo certo comprare della “ferramenta” apposta ma di cucchiai in casa ne avevo… solo che mettendo di fianco un cucchiaio e un cucchiaino, io stesso facevo a fatica a distinguerli: decontestualizzando, quindi capii che se stavo facendo fatica io, non avrei potuto pretendere di riuscire ad addestrare una rete neurale in grado di far meglio di me. Non sono così bravo, come addestratore. 😀
Alla fine scelsi degli shampoo perché:
- ne avevo due in casa, quindi più classi;
- sono dei manufatti come le forbici;
- sono molto simili ma io riesco a distinguerli.
In generale nel Deep Learning si usano tre insiemi di esempi per addestrare e valutare la rete. AutoML non fa eccezione:
training set, per l'apprendimento diretto;validation set, per la correzione dei pesi;testing set, per giudicare la rete.
La rete NON impara sul testing set.
AutoML chiede, per ogni classe, di fornire almeno 100 immagini che siano poi comparabili (per caratteristiche, difficoltà eccetera) alle immagini data alla rete per la validazione.
Dato che volevo mettere alla prova il tutto - e anche perché non avevo molto tempo - sono quindi partito da:
- 2 oggetti molto simili;
- per ciascun oggetto, ho scattato solamente 3 fotografie invece delle 100 richieste;
- avrei inoltre giudicato usando delle immagini (testing set) più difficili di quelle utilizzate per l'addestramento.
Inoltre, avere solo 3 immagini al posto di 100, avrebbe aiutato a provare lo scenario – tutt'altro che remoto – nel quale un ipotetico cliente fornisca un numero ridottissimo di esempi per l'apprendimento.
Ecco i due oggetti e le sei fotografie, in tutto il loro splendore.

Data Augmentation
Come avrei fatto a procurarmi 100 immagini invece di 6?
Data augmentation is the process of increasing the amount and diversity of data. We do not collect new data, rather we transform the already present data.
Si possono creare varie immagini artificiali partendo da un'immagine vera, concatenando variazioni come:
- rototraslazioni;
- pan/tilt;
- zoom-in/zoom-out;
- aggiunta di rumore;
- copertura di zone;
- variazioni nello spazio colore;
- eccetera.
Ci sono almeno tre librerie in Python per fare questo:
- una era albumentations: molto buona e persino in grado di creare gli XML degli oggetti; infatti, partendo da una immagine con uno o più rettangoli noti, per trasformazioni geometriche è in grado di ricavare i rettangoli delle immagini derivate. Per apprendere, la rete ha bisogno che si includano in rettangoli gli oggetti da classificare, assegnandogli ovviamente l'opportuna label: non riuscivo a capire come salvare le immagini manipolate, perché tutta la documentazione si riferiva a una pipeline in memoria e non mi sono concentrato oltre ma credo meriti un approfondimento;
- un'altra era imgaug: con caratteristiche simili alla precedente ma che richiede un momento in più di concentrazione;
- una terza, Augmentor, non creava gli XML ma almeno aveva della documentazione comprensibilissima, molto semplice e indicava chiaramente come creare i file rapidamente, quindi scelsi questa.
Augmentor
Con Augmentor è possibile generare innumerevoli immagini con le tecniche summenzionate: un esempio di pipeline – quella che ho utilizzato – è la seguente.
import Augmentor
p = Augmentor.Pipeline("./augmented/regolatore/")
p.rotate(probability=1, max_left_rotation=5, max_right_rotation=5)
p.flip_left_right(probability=0.5)
p.zoom_random(probability=0.5, percentage_area=0.8)
p.flip_top_bottom(probability=0.5)
p.random_erasing(0.5, 0.5)
p.resize(probability=1.0, width=1024, height=1024)
p.sample(100)
Esempio di immagini creata

Labelling and Bounding
Alla fine:
- ho creato 108 immagini, per ciascuna classe;
- le ho caricate su GCP;
- in poco più di paio d'ore ho etichettato e circoscritto 216 immagini.
Addestrare la rete con immagini di oggetti singoli avrebbe poi reso ulteriormente interessante vedere come se la sarebbe cavata con immagini multioggetto.
Una schermata di Google AutoML Vision in fase di Labelling e Bounding

Ancora prima di addestrare la rete, è possibile scaricare un CSV con i bounding per eventuali processamenti con altri sistemi e il successivo confronto con sistemi in grado di utilizzare lo stesso formato del CSV o modificandolo con semplici trasformazioni.
Training
Ho scelto un addestramento di qualità media: dato che il mio obiettivo era scaricare i modelli e usarli “on the Edge” non avrei voluto attendere troppo.
AutoML mi suggeriva, per meno di 1000 immagini, un paio di “node hours” proponendomi però 24 come default: in caso la rete non riesca significativamente a migliorare dopo un certo numero di epoche, Google interrompe comunque l'addrestramento, facendo pagare solo l'effettivo tempo utilizzato. Una “node hour” è un'ora sui loro nodi di GPU molto potenti.
Non avevo idea né del tempo che sarebbe servito, né dei soldi che avrei speso: lanciai la simulazione e andai a dormire. La mattina dopo, una mail mi informava che la mia rete era stata addestrata in 3 ore e mezza circa e che i file di modello erano scaricabili.
Quanto mi era costato? 62$ ma grazie a 300$ di bonus, il tutto era di fatto gratis.
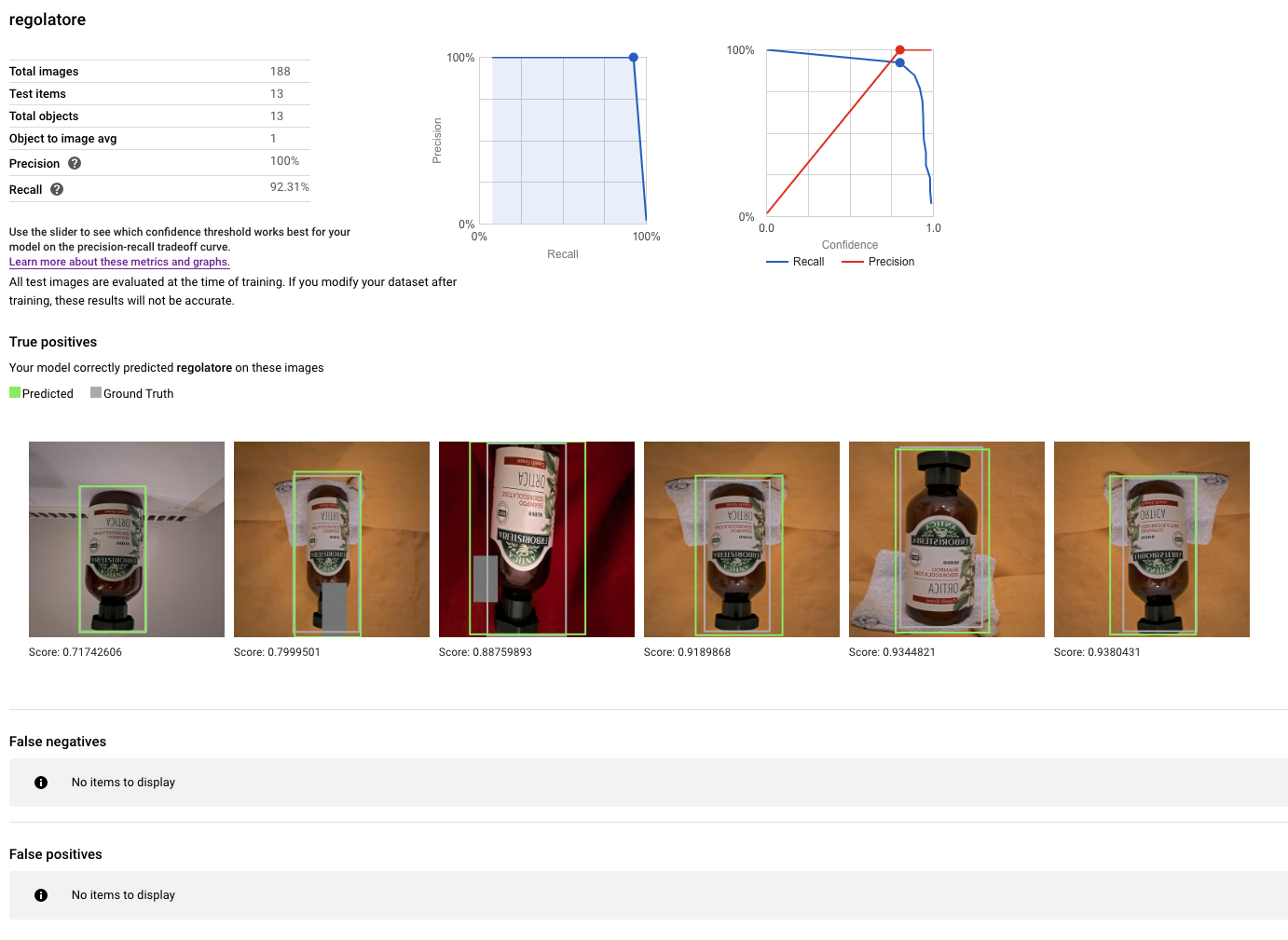
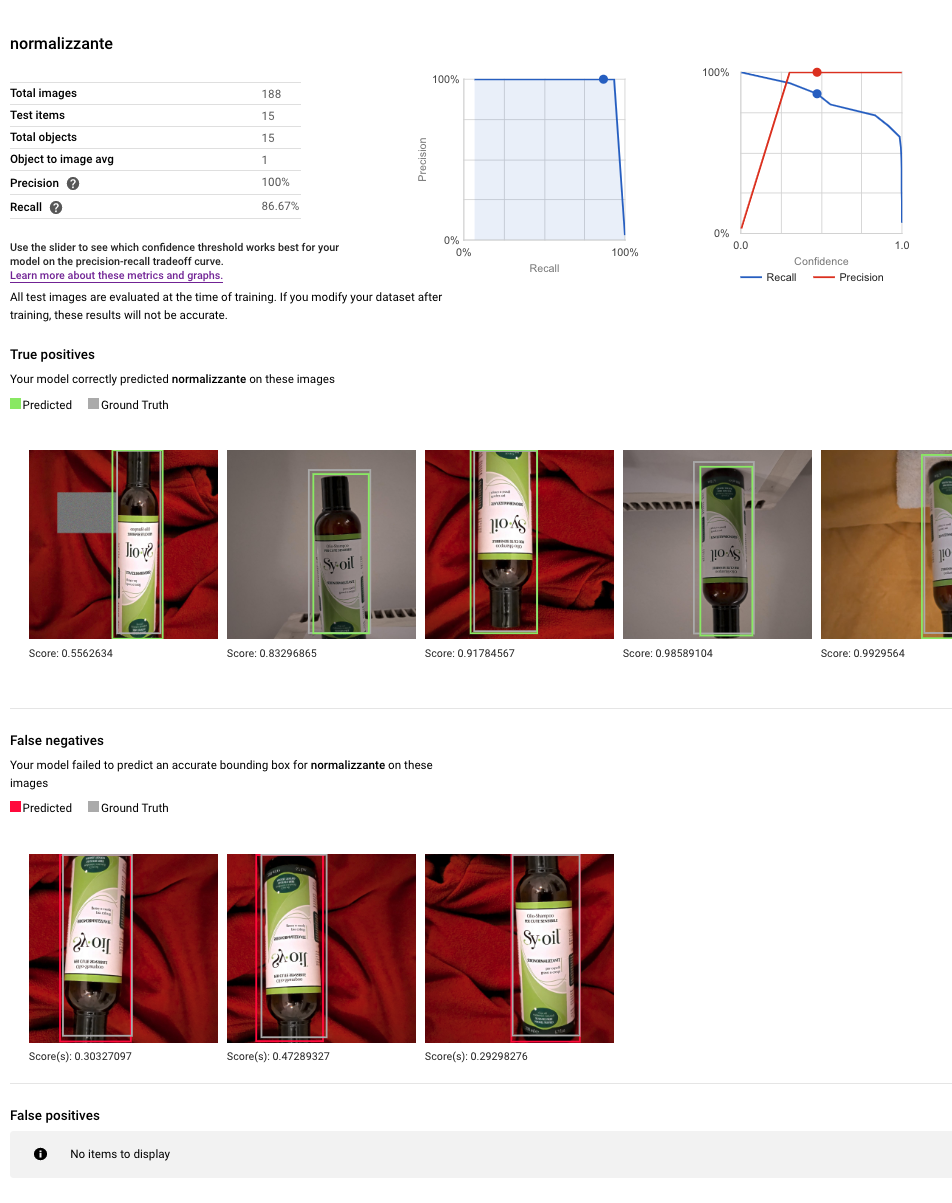
Due diagrammi di sintesi prodotti da AutoML
Sul regolatore
Sul normalizzante
Un po' di codice
AutoML produce tre uscite:
- TensorFlow
- TensorFlow Lite
- TensorFlow Js
Per provare, mi sono concentrato sul sottocaso Tensorflow.js perché offriva uno snippet JavaScript: l'ho poi migliorato passando anche a una versione con webcam, di cui, però, non sono riuscito a passare lo stream al modello.
Indipendentemente quindi dalla qualità della rete, estrarre l'immagine passando da un img determina dei tempi di calcolo abbastanza alti (dai 3 ai 4 secondi abbondanti): ho provato a mettere in memoria l'immagine ma non ho ottenuto miglioramenti. Per il momento, mi accontento e guardo la sola bontà della rete che è comunque un dato molto interessante.
Il cuore del codice
Sorvolando sul contorno, il codice di base è questo:
async function run() {
const img = document.getElementById('shampoo')
const options = {score: 0.3, iou: 0.5, topk: 20}
const model = await tf.automl.loadObjectDetection('model.json')
const predictions = await model.detect(img, options)
// use predictions (it's an array)
}
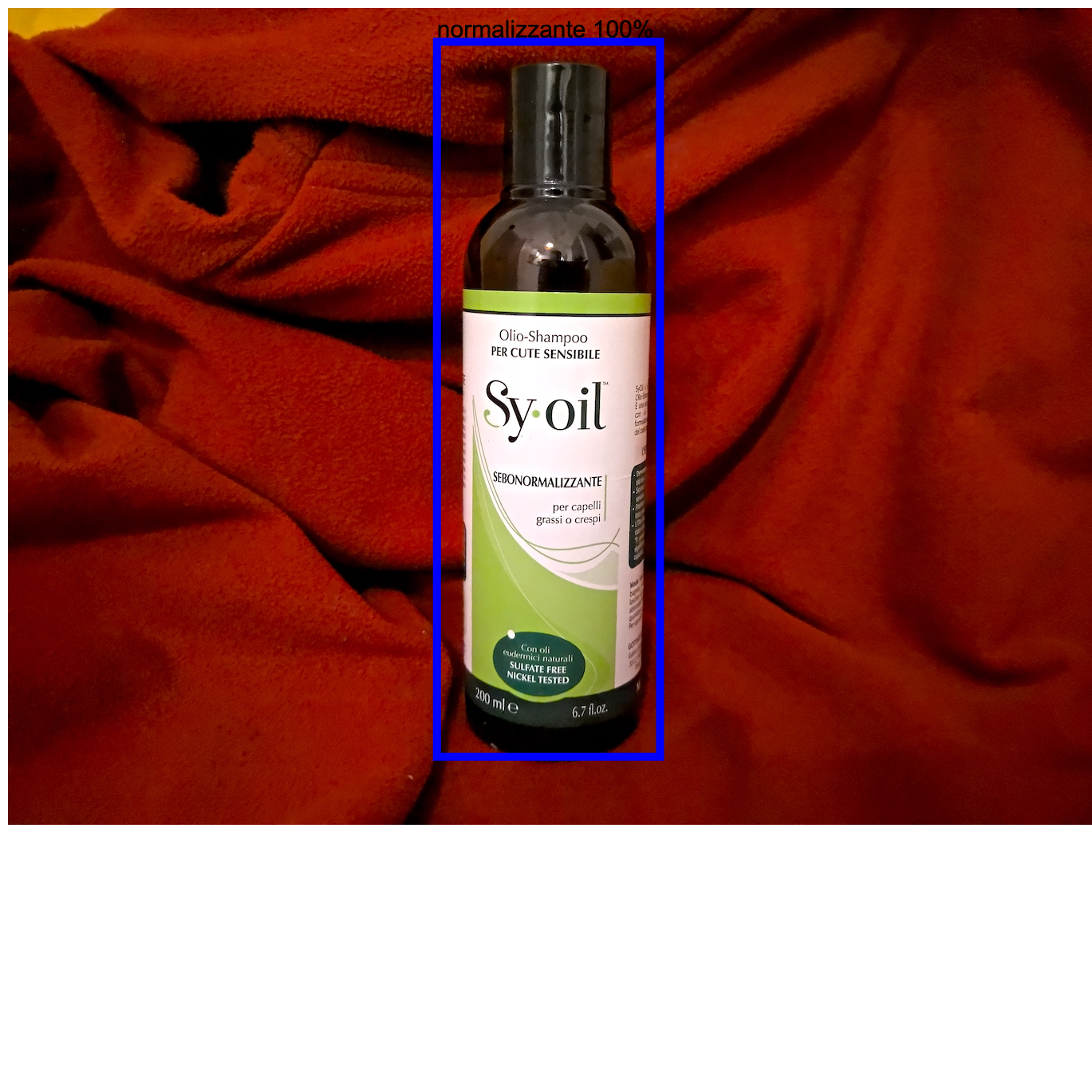
Il “testing set”
Uso il virgolettato perché sono prove singole su casi che ritengo difficili o importanti, non un vero “set” di immagini con prestazioni della rete misurate.
Questa è la convenzione per capire al volo la corretta classificazione:
- Shampoo Normalizzante => rettangolo BLU
- Shampoo Regolatore => rettangolo ROSSO


Falsi positivi


A questo punto mi sono chiesto: come se la caverebbe con qualcosa di simile ma chiaramente diverso da una delle due classi?
Immagini esterne
Ho quindi provato con la fotografia di uno shampoo che non avevo in casa ma presa su internet, volutamente simile alle due con le quali ho addestrato la rete.

A questo punto mi è venuto un dubbio: non è che qualsiasi oggetto lo classifichi con una delle due classi?
Ho quindi provato con qualcosa di palesemente diverso: una mela.

Prove con webcam
Qui ho cambiato un po' i canvas per renderli più semplici e leggibili:
- niente label in alto
- fa fede il colore
- normalizzante: blu
- regolatore: rosso
- percentuale di confidenza al centro del rettangolo di identificazione

Conclusioni
AutoML
- è davvero semplice
- mi sembra funzioni bene (classification buona, detection direi ottima)
- è robusto (ricordiamo: 3/100 e test con immagini ben diverse)
- TensorFlowJs mi pare lento, forse a causa delle dimensioni delle immagini in addestramento: non ho provato gli altri output (TensorFlow e TensorFlow Lite)
Riassumendo: Google AutoML Vision è davvero un bel prodotto.
Shut up and show me the code
Ho messo tutto su GitHub
😀
Cover Photo by Rachel Lynette French on Unsplash