Test di integrazione su AWS: una soluzione custom


Problema
Esistono diverse soluzioni gestite per la continuous integration ma spesso richiedono delle modifiche al workflow degli sviluppatori. Un nostro cliente, con un team molto impegnato, ci ha chiesto di sviluppare un sistema per testare in modo automatico l'integrazione di un insieme di microservizi distribuiti su più repository, senza modificare il quotidiano flusso di lavoro degli sviluppatori.
Soluzione sviluppata
Utilizzando diversi servizi di AWS, abbiamo creato questo sistema.
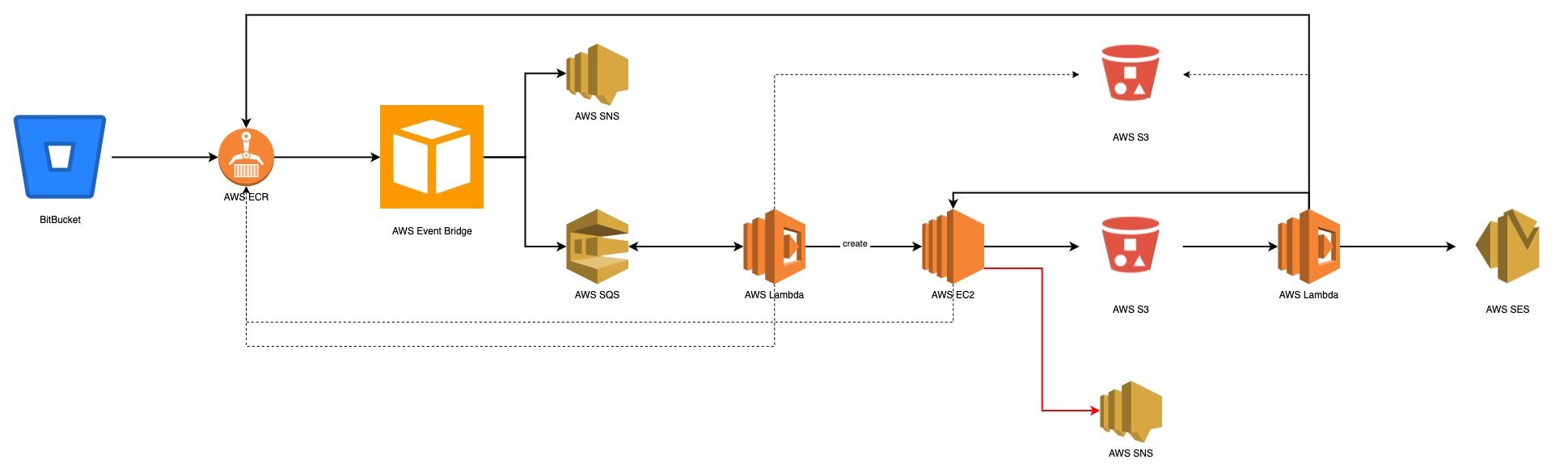
- Su BitBucket, una
pushcon un determinatotagaziona una pipeline (il file convenzionalmente chiamatobitbucket-pipelines.yml) con questa azione, BitBucket consente di eseguire operazioni arbitrarie all'interno di un suo container effimero e, nel nostro caso, l'azione è la preparazione di una nuova immagine Docker, che viene depositata su di un repository di immagini AWS ECR. - AWS Event Bridge, configurato opportunamente, avverte dell'avvenuto deposito:
- SQS attiverà a sua volta una AWS Lambda.
- La Lambda recupera da AWS Secrets Manager ulteriori informazioni costanti, come i nomi dei vari repository ECR, le variabili d'ambiente necessarie e altri parametri: anche se non ci sono veri segreti, grazie a AWS IAM e si potrebbe usare AWS S3 memorizzando semplicemente tutto in un file
JSON, abbiamo indicato questa opzione per completezza. - Raccolte le varie informazioni da ECR e da SecretesManager/S3, la lambda istanzia una AWS EC2 basata su di una AWS AMI personalizzata, passandogli, in fase di creazione, tutti i dati necessari in
/tmp/data.jsontramite l'opzioneUserData. - La EC2, disponendo quindi di tutto il necessario, al suo boot eseguirà uno script, il quale:
- scaricherà da ECR tutte le immagini Docker indicate, nelle versioni indicate;
- costruirà il relativo
docker composeed eseguirà tutti i test di integrazione indicati dai programmatori; - salverà i risultati in file di log, json individuali e un json complessivo;
- in caso di successo, salverà tutto su di un bucket S3 e, in caso di fallimento in uno dei punti precedenti, notificherà tramite SNS.
- Alla ricezione, il bucket S3 farà eseguire una seconda Lambda, la quale:
- distruggerà la EC2, se i test saranno andati a buon fine (in caso di fallimento, non la distruggerà per una comoda ispezione);
- modificherà il tag stabile su AWS ECR, sostituendolo con il valore nuovo attribuito su BitBucket;
- invierà una mail con report e allegati.
Qualche snippet utile estratto dal progetto
Ottenere l'elenco dei tag ECR di un dato repository
def ecr_tags_get(credentials):
ecr = boto3.client('ecr', region_name=credentials['AWS_REGION'])
return ecr.list_tags_for_resource(resourceArn=arn)
Aggiornare un tag ECR in un dato repository
def ecr_tag_update(region, account_id, repo):
ecr = boto3.client(
'ecr',
region_name=region
)
arn = 'arn:aws:ecr:{}:{}:repository/{}'.format(region, account_id, repo['name'])
repository_tags = ecr.list_tags_for_resource(resourceArn=arn)
response = ecr.tag_resource(
resourceArn=arn,
tags=[
{
'Key': 'stable_tag',
'Value': repo['tag']
},
]
)
Creare un oggetto da un file JSON su S3
def repos_name_get(credentials):
s3 = boto3.resource('s3')
content_object = s3.Object(
credentials['AWS_S3_BUCKET'],
credentials['AWS_S3_BUCKET_FILE_NAME']
)
file_content = content_object.get()['Body'].read().decode('utf-8')
return json.loads(file_content)
Creare una EC2 con un dato profilo IAM e con uno UserData arbitrario (eventuale esecuzione di uno script inclusa)
Per la creazione di una EC2, si veda https://github.com/carlok/miscellaneous/blob/main/aws/ec2.py, integrando con
user_data_script = '''#!/bin/bash
echo '{}' > /tmp/data.json
'''.format(f_data_json)
instances = ec2.create_instances(
...
UserData=user_data_script
)
Distruzione di una EC2
def ec2_destroy(region, instance_id):
ec2 = boto3.resource(
'ec2',
region_name=region
)
ec2.instances.filter(InstanceIds = [instance_id]).terminate()
Invio di mail con allegato json
def email_send(region, subject, sender, recipient, mtext, results, file_name):
CHARSET = "utf-8"
mhtml = '<pre>\n{}</pre>'.format(mtext)
client = boto3.client(
'ses',
region_name=region
)
msg = MIMEMultipart('mixed')
msg['Subject'] = subject
msg['From'] = sender
msg['To'] = recipient
msg_body = MIMEMultipart('alternative')
textpart = MIMEText(mtext.encode(CHARSET), 'plain', CHARSET)
htmlpart = MIMEText(mhtml.encode(CHARSET), 'html', CHARSET)
msg_body.attach(textpart)
msg_body.attach(htmlpart)
att = MIMEApplication(json.dumps(results))
att.add_header('Content-Disposition', 'attachment',
filename='{}.json'.format(file_name))
msg.attach(msg_body)
msg.attach(att)
try:
response = client.send_raw_email(
Source=sender,
Destinations=[
recipient
],
RawMessage={
'Data': msg.as_string(),
}
)
except ClientError as e:
print(e.response['Error']['Message'])
Conclusione
Questo sistema, oltre a risolvere il problema per il quale è nato, costituisce un buon esempio per altri casi d'uso (creazione di combinazioni di versioni custom di progetti costituiti da vari repository o altre elaborazioni gestite con una parte su di una macchina virtuale effimera).
--
Photo by Nicole Wolf on Unsplash